
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 어셈블리어
- 워게임
- 리버싱
- wargame
- 리눅스
- radare2
- 시스템 프로그래밍
- 커널
- Leviathan
- 프로그래밍
- Pwnable.kr
- 취약점
- 시스템프로그래밍
- 리눅스 커널
- pwn.college
- px4
- 시스템해킹
- 알고리즘
- write up
- css
- Bandit
- C++
- 컴퓨터구조
- C언어
- 시스템
- 드론
- pwncollege
- 리눅스커널
- 시그널
- kernel
- Today
- Total
Computer Security
#1 XPATH를 활용한 네이버 항공권 최저가 불러오기 본문
일단 네이버 항공권 웹 자동화를 하기 위해선
Chromedriver 와 selenium 설치가 필요하다.
VS code를 통해 진행 하도록 하겠다.
목표
네이버 항공권에서 내가 가는 날짜, 오는 날짜, 가는곳을 선택하고 최저가 부분을 출력 하기!
나는 6월27~28일 제주도 여행을 예시로 하겠다.
1. 바탕화면에 새로운 빈 폴더를 만든다.
2.빈 폴더 안에 Chromedriver.exe를 넣는다.
3.셀레니움이 설치가 안되어 있다면,cmd에 들어가서 pip install selenium 입력 하여 설치
코드 작성하기
1.from selenium import webdriver
- 셀레니움 라이브러리에서 웹드라이버를 받아온다.
2.browser = webdriver.Chrome()
- 크롬 브라우저를 연다.
3.url = 'https://flight.naver.com/'
- 네이버 항공권 사이트인 https://flight.naver.com/ 을 활용해 url을 만들어준다.
4.browser.get(url)
- 네이버 항공권 사이트에 접속한다.
5. HTML을 살펴봤을때, 가는날 부분을 누르기 위해선 HTML속성에 접근해야한다.
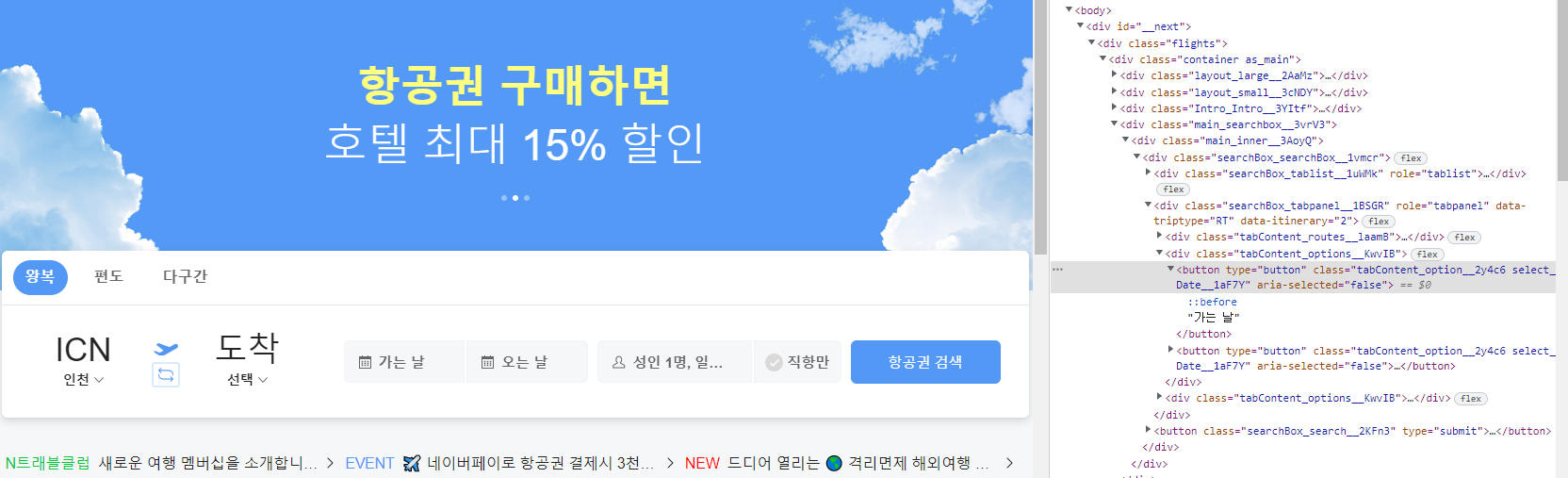
6. from selenium.webdriver.common.by import By
- 우리는 XPATH를 통해 값을 얻을 건데, XPATH로 하는것을 명시해주기 위해 하나 더 import해준다. 이 By는 텍스트로할지, XPATH로 할지 등 을 정해주는 역할을 해준다.
7. begin_date = browser.find_element(By.XPATH, '//button[text()="가는 날"]')
- begin_date 라는 가는날에 대한 데이터를 저장할 변수를 만들고, HTML속성에 button과 "가는 날"부분을 담을 수 있도록 해준다.
8.begin_date.click()
- begin_date에 저장된 데이터 부분을 클릭 해준다.
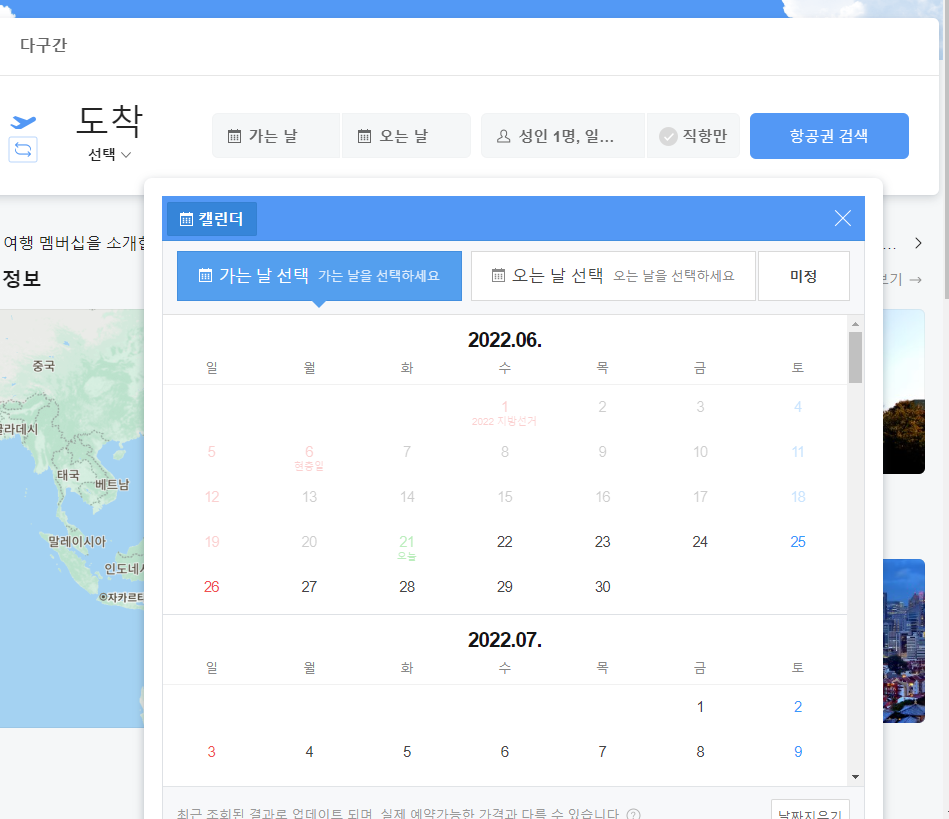
이런식으로 클릭 된 것을 볼 수 있다.
6월 27일부터 28일까지 여행 간다라 쳐보자.
위에 가는날을 했던 방식과 같이 HTML속성을 확인해 코드를 작성 해준다.
9.day27 = browser.find_elements(By.XPATH,'//b[text()="27"]')
- day27이라는 변수안에 27에 대한 속성데이터 저장(그러나 페이지 내에 27이란 부분은 2개이상일 것 같기에, element가 아닌 elements 로 설정 하자. (b태그로 작성되어있다)
10.day27[0].click()
- day27이란 데이터 안에는 여러 27있는데, 예를들어 6월27일 7월27일 등등 우린 6월 27일날 여행을 갈 것이기에 받아온 데이터들 중 가장 첫번째인 day27[0] 부분을 클릭한다.
11.day28 = browser.find_elements(By.XPATH,'//b[text()="28"]')
day28[0].click()
- 위 코드 처럼 28도 똑같이 진행한다.
자 그러면, 사이트 상황은 현재
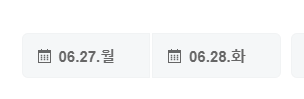
이렇게 가는날과 오는날이 들어가 있을 것이다.
12.arrival = browser.find_element(By.XPATH, '//b[text()="도착"]')
arrival.click()
- 이번엔 도착지를 설정 하기 위해 도착을 클릭하도록 한다.
14.domestic = browser.find_element(By.XPATH, '//button[text()="국내"]')
domestic.click()
- 제주도로 여행갈 예정이기에 국내 카테고리를 클릭하도록 한다.
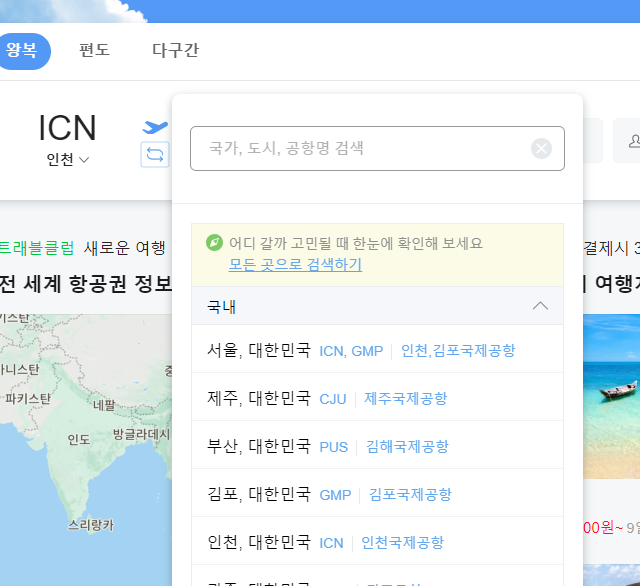
15.jeju = browser.find_element(By.XPATH,'//i[contains(text(),"제주국제공항")]')
jeju.click()
- 여기서 제주국제공항을 클릭하도록 한다.
- 이때, 제주국제공항말고도 묶여있는 부분이 존재할 수 있으니,
- contains(text(),"제주국제공항")을 이용해 제주국제공항을 품고있는 부분 전체를 클릭하도록 해준다.
16.search = browser.find_element(By.XPATH,'//span[contains(text(),"항공권 검색")]')
search.click()
- 항공권 검색을 눌러준다.

그럼 이렇듯 기다리는 화면이 출력되는데 이때, 컴퓨터가 다음 동작을 수행하게 된다면, 에러가 일어날 수 있으므로 기다리는 부분을 만들어 주도록 하자.
17.from selenium.webdriver.support.ui import WebDriverWait
- 어떤 element가 나올때까지 웹을 기다리는 부분을 import 해준다.
18.from selenium.webdriver.support import expected_conditions as EC
- 기다리는 조건을 무엇으로 할지 에관한 부분을 import해준다.

이 div태그가 나올때 까지 기다리도록 코드를 작성 해보자.
19.elem = WebDriverWait(browser, 30).until(EC.presence_of_element_located((By.XPATH,'//div[@class="domestic_Flight__sK0eA result"]')))
- WebDriverWait(browser, 30) 웹 브라우저를 최대 30초 동안 기다릴 껀데, 언제까지 기다리냐(until) presence_of_element_located : 어떤 element가 표시 될때까지 기다려 달라. 무슨 element냐면 여기선div[@class="domestic_Flight__sK0eA result" 이다.
20.print(elem.text)
- 저 네모난 부분의 데이터를 출력해준다.
21. browser.quit()
- 브라우저를 종료 시킨다.
위와 같이 작성하게 되면, 오류가 발생할 수 있다.
예를들어 가는날 오는날 등을 선택할때, 아주 약간의 딜레이가 있다면, 컴퓨터는 매우 빠르게 클릭되기에 딜레이가 될때 클릭이 된다면 컴퓨터는 다음동작으로 넘어가지 못하고 중단될 수 있다.
이를 방지하기위해 위에 부분처럼 어떤 element가 나올때까지 기다려주는 함수를 작성 해보자.
22.def wait_until(xpath_str):
WebDriverWait(browser, 30).until(EC.presence_of_element_located((By.XPATH, xpath_str)))
이렇게 함수를 만든뒤, 클릭되는 부분마다 넣어주면, 코드가 완성된다.
완성된 코드
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def wait_until(xpath_str):
WebDriverWait(browser, 30).until(EC.presence_of_element_located((By.XPATH, xpath_str)))
browser = webdriver.Chrome()
browser.maximize_window()
url = 'https://flight.naver.com/'
browser.get(url)
begin_date = browser.find_element(By.XPATH, '//button[text()="가는 날"]')
begin_date.click()
wait_until('//b[text() = "27"]')
day27 = browser.find_elements(By.XPATH,'//b[text()="27"]')
day27[0].click()
wait_until('//b[text() = "28"]')
day28 = browser.find_elements(By.XPATH,'//b[text()="28"]')
day28[0].click()
wait_until('//b[text()="도착"]')
arrival = browser.find_element(By.XPATH, '//b[text()="도착"]')
arrival.click()
wait_until('//button[text()="국내"]')
domestic = browser.find_element(By.XPATH, '//button[text()="국내"]')
domestic.click()
wait_until('//i[contains(text(),"제주국제공항")]')
jeju = browser.find_element(By.XPATH,'//i[contains(text(),"제주국제공항")]')
jeju.click()
wait_until('//span[contains(text(),"항공권 검색")]')
search = browser.find_element(By.XPATH,'//span[contains(text(),"항공권 검색")]')
search.click()
elem = WebDriverWait(browser, 30).until(EC.presence_of_element_located((By.XPATH,'//div[@class="domestic_Flight__sK0eA result"]')))
print(elem.text)
browser.quit()결과 값

'프로그래밍 > Python 웹 스크래핑' 카테고리의 다른 글
| #3 XPATH를 이용한 주요 뉴스 불러오기 (0) | 2022.06.29 |
|---|---|
| #2 XPATH를 활용한 네이버웹툰 실시간 급상승 불러오기 (0) | 2022.06.28 |

